0 引言
雷达技术的飞速发展使得雷达数据采集系统的数据采集速率越来越高,雷达数据记录回放系统需要更高的传输速率[1-2]。PCIE总线作为新一代的传输总线,具有很高的传输速率,基于PCIE总线的直接内存存储(DMA)在数据传输中可以减少CPU的干预,减轻CPU的负担,大幅提高系统的性能[3-6],目前主要采用基于PCIE总线的DMA来实现雷达数据记录回放系统的高速数据传输。基于PCIE总线的DMA主要分为BLOCK DMA和分散集聚DMA两种方式,其中分散集聚DMA由于可以通过描述符链表将分散的内存集聚起来,可申请的内存更大,经过一次DMA启动,便能完成FPGA与各个物理分散内存之间的数据传输,能够减轻CPU的负担,优势更为明显[7-9]。
目前分散集聚DMA中描述符链表的传输与更新需要DMA控制器与驱动频繁的握手,每一个描述符对应内存完成数据传输以后,DMA控制器都需要向驱动更新此描述符并获取新的描述符[10],浪费了很多时间。本文提出了一种改进分散集聚DMA的实现方式,一次性将描述符链表全部传输给DMA控制器,之后便不需要与驱动握手更新描述符以及获取新的描述符,节省了因描述符切换需要的握手时间,提高了数据传输速度。而且,DMA控制器设计了多个数据通道,可以在实际应用中根据需要实现雷达数据的流水传输与处理。
1 现有分散集聚DMA原理
因为分散集聚DMA申请的内存是物理不连续的,所以上位机在申请一定大小的内存时,会生成描述符链表,描述符链表中的每一个描述符都指向了一小块物理连续的内存,描述符中定义了控制状态信息和内存信息。其中,描述符最后32 bit是一个指向下一个描述符的指针,这个指针将各个描述符连接成描述符链表,由此就可以映射到整个物理不连续的内存[11]。
在传统分散集聚DMA的传输过程中,如图1所示,首先DMA控制器从驱动读取描述符链表中的一个描述符并存到描述符引擎中,DMA控制器根据描述符引擎中的信息完成对应内存的数据传输后,描述符更新引擎将此描述符的更新信息传到描述符链表中,然后描述符引擎通过指向下一个描述符的指针向驱动获取下一个描述符的信息,由此进行下一个描述符对应内存的数据传输。此方式在传输完成一个描述符对应内存的数据后,需要等待描述符更新引擎更新描述符信息和描述符引擎读取下一个描述符的信息,降低了数据传输的持续性。
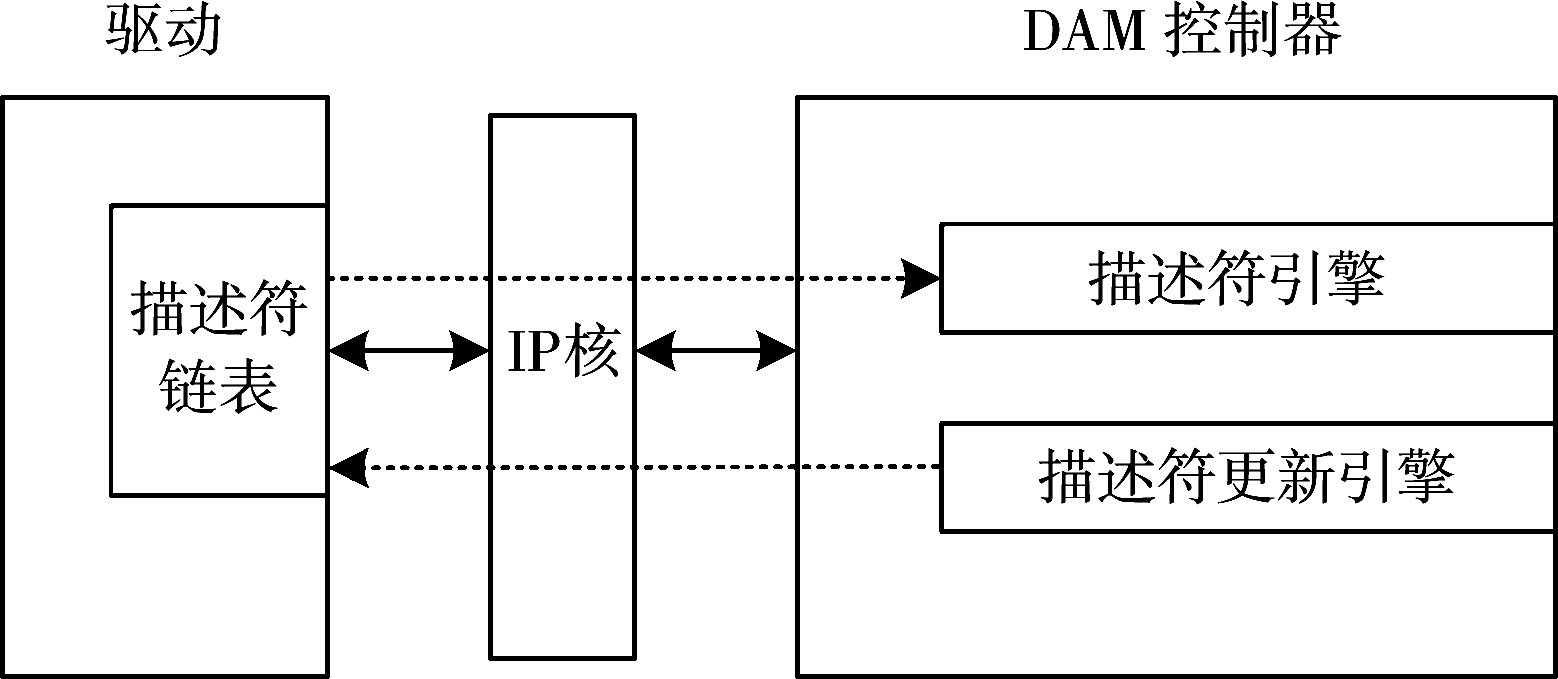
图1 现有分散集聚DMA示意图
2 改进分散集聚DMA设计
2.1 DMA控制器设计
针对驱动与DMA控制器频繁握手的不足,本设计在上位机驱动中对描述符链表作了提取处理,由于描述符(32 B)中的保留位以及状态位等在DMA控制器中是无用信息,因此本设计直接选取了有用的上位机内存地址位(8 B)和数据长度位(4 B)发送至DMA控制器,描述符其他数据不再发送。当DMA控制器初始化以后,驱动直接将所有描述符的系统地址位和数据长度位发送至描述符引擎,如图2所示,此后,描述符引擎便不需要与驱动握手。

图2 改进后分散集聚DMA示意图
由于改进后分散集聚DMA是应用在雷达数据记录回放系统中,雷达数据量非常大,远大于一个描述符对应的内存(通常4 KB),不会出现实际传输数据小于描述符内存的情况,因此不需要更新描述符中实际传输数据大小。现有描述符更新引擎的一个重要作用是当一个描述符对应内存完成数据传输以后,通知驱动此内存可进行数据读取或写入,可是在分散集聚DMA实际传输过程中都是所有描述符对应内存完成数据传输以后,上位机才会对内存进行数据读取或写入工作,不会对单个描述符内存进行操作,而且若数据传输中出现错误,由DMA控制器直接向驱动发送错误中断,因此本次设计中取消了描述符更新引擎,不会增加数据传输的错误率,而且节省了每次更新描述符DMA控制器与驱动的握手时间。
改进后的DMA控制器在进行DMA数据传输的工作过程如图3所示。
1)驱动初始化DMA控制器,配置DMA寄存器;
2)驱动将描述符链表中每个描述符的数据传输长度和上位机内存地址提取出来,发送至DMA控制器并存入描述符引擎中;
3)启动DMA操作,DMA控制器根据第一个描述符中的内存起始地址和数据长度信息控制数据通道与上位机内存进行DMA数据传输;
4)当数据通道与第一个描述符对应内存完成数据传输时,直接通过描述符引擎连接到下一个描述符所对应的内存地址,而不需要通过描述符指针去获取下一个描述符,当所有的描述符对应的内存完成数据传输操作以后,DMA引擎停止工作,DMA控制器发出中断请求信号,结束此次DMA的传输。
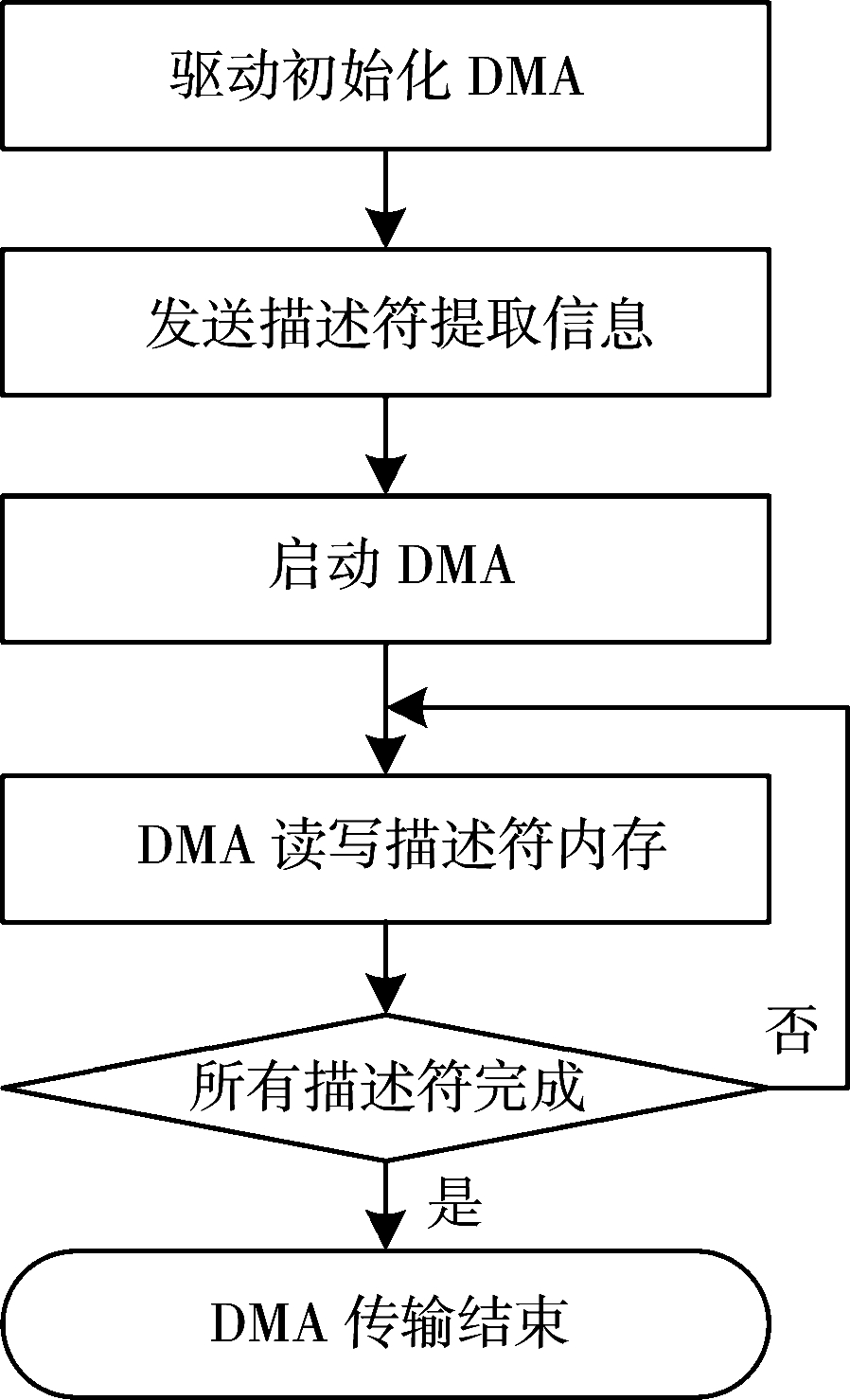
图3 DMA数据传输工作过程
其中,描述符的切换是通过实时数据传输长度与描述符引擎中存储的描述符内存数据的长度进行比较判断的,当两者相同时,连接到下一个描述符继续进行DMA传输。
当然,驱动与DMA控制器是相对应的,驱动通过对DMA控制器的读写操作完成DMA初始化,初始化完成以后,驱动提取出各个描述符中内存起始地址和数据长度信息发送给DMA控制器,然后启动DMA开始进行DMA数据传输,当接收到DMA控制器发送的中断以后,清除中断并结束DMA操作[12-13]。
在此设计中,一次性将描述符链表中各个描述符中的内存起始地址和数据长度信息传输至描述符引擎,并通过已传输数据长度判断是否切换描述符链表中的地址,减少了DMA控制器与驱动的握手次数,能够使DMA控制器连续不断地传输数据,保持了数据传输的持续性,节省了每次描述符对应内存传输完成后更新、切换描述符的等待时间,提高了数据传输速度。
2.2 多通道设计
针对雷达数据记录回放系统多任务数据传输的需求,DMA控制器至多可提供8个数据通道,每个通道都有独立的寄存器组,包括控制状态寄存器、地址寄存器、传输长度寄存器等[14-15]。
现有雷达信号处理系统在处理雷达数据时均有一定的时延,雷达数据通过DMA控制器发送至某一雷达信号处理系统后,雷达信号处理系统需要一定的时间处理雷达数据,因此会浪费DMA传输带宽。对此,可以通过数据通道连接多个雷达信号处理系统,雷达数据依次通过各个通道传输到不同的处理系统中,能够实现雷达数据的流水处理。
例如,当8个雷达信号处理系统通过8个数据通道连接DMA控制器时,如图4所示,第一幅雷达图像原始数据可以通过通道0传输至雷达信号处理系统0,第二幅图像数据切换至通道1传输至处理系统1,以此类推,可以实现雷达数据在8个处理系统中流水处理,雷达数据处理速度提高了8倍。
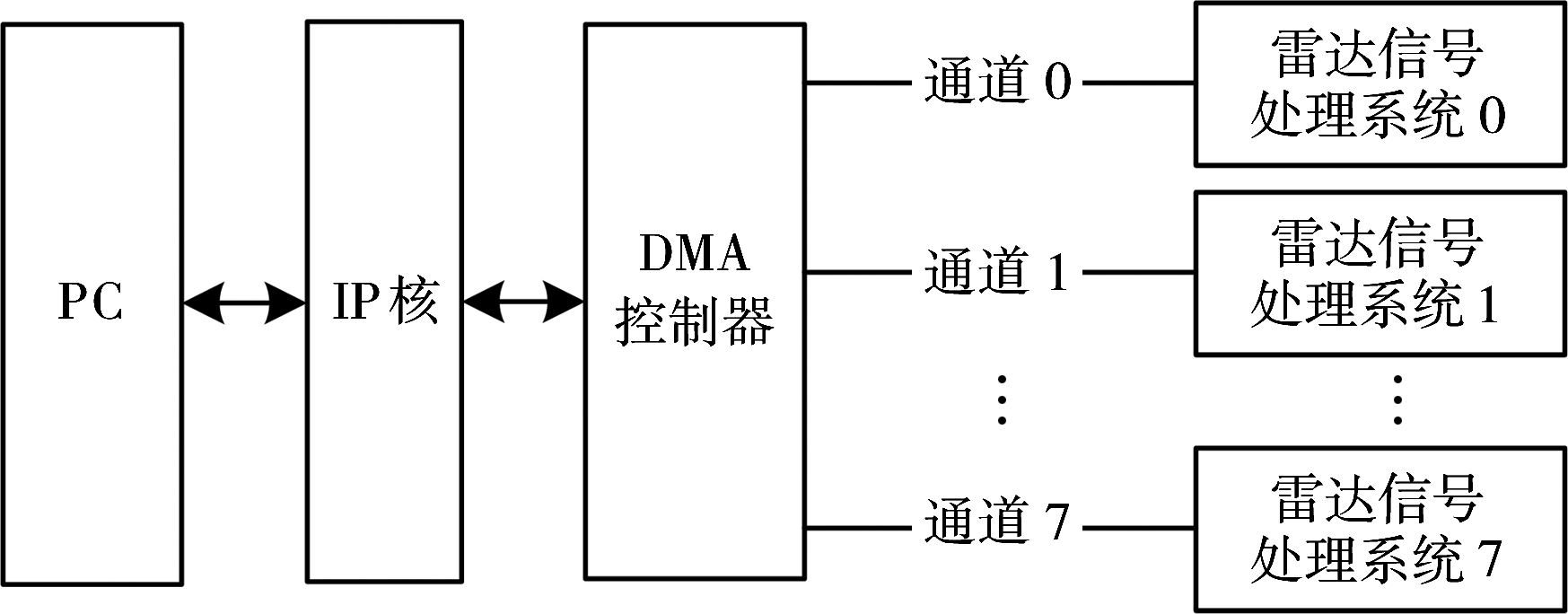
图4 多通道传输
在实际应用中,可以根据雷达图像数据大小和数据传输速率适当选择信号处理系统的数量,不需要浪费信号处理系统处理数据的时间,从而充分利用DMA传输带宽,可以实现雷达数据的高速传输,提高雷达数据处理速度。在本文DMA设计中,将数据通道的选择权直接通过接口交给用户程序,用户可在上位机直接决定选择某个通道进行数据传输,也可随时切换通道。
3 改进分散集聚DMA数据传输性能分析
由于分散集聚DMA在数据传输过程中,DMA初始化、中断处理、寄存器读写等需要驱动与DMA控制器握手的时间受硬件、驱动等客观因素影响,甚至相同条件下连续两次测试花费的时间也是不一样的,因此不存在一个精确的传输速度。本节仅从传输数据包中有效数据的比例分析传输速度。
基于PCIE总线的分散集聚DMA传输速度理论分析基于以下假设:
1)每一个描述符对应4 KB内存;
2)每个TLP包最大有效载荷128 B;
3)最大读请求128 B;
4)TLP包头3个双字12 B;
5)一个应答信号开销8 B;
6)暂时不考虑DMA初始化、中断处理等其他影响因素。
基于上述假设,现有分散集聚DMA写一个描述符对应内存的数据需要传输非有效数据的损耗如表1所示。
表1 现有DMA写一个描述符进行DMA数据传输损耗
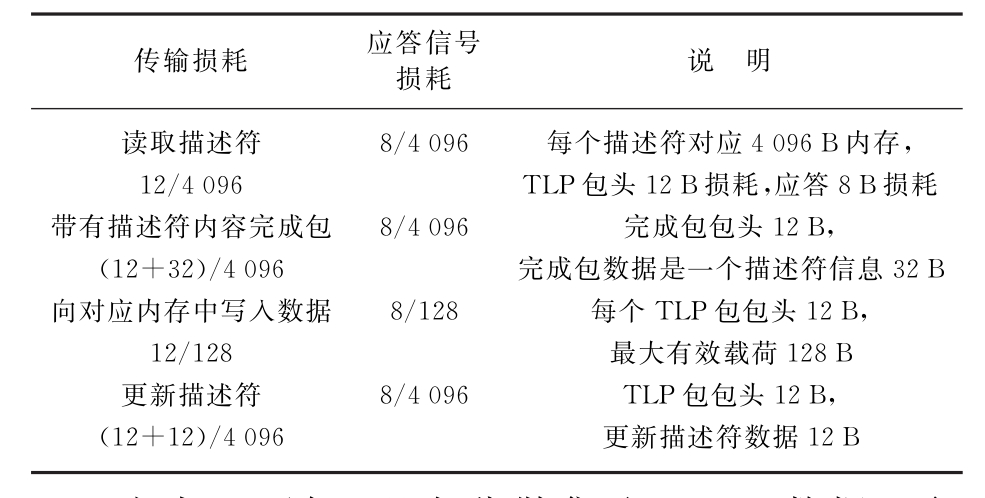
由表1可知,现有分散集聚DMA数据上行(DMA写)过程中,每传输一个描述符内存数据(4 096 B),读取描述符、接收完成包、更新描述符以及各自应答信号损耗的字节数为12+8+12+32+8+12+12+8=104,传输4 096 B有效数据,需要传输的TLP包个数为4 096/128=32,每传输一个TLP包的字节损耗是12+8=20,传输4 096 B有效数据损耗共计
104+32×20=744 B
所以,现有分散集聚DMA数据上行损耗为
744/(4 096+744)=15.37%
我们知道,PCIE Gen2×4链路理论传输速度为2 GB/s,现有DMA有效数据上行传输速度极限为
2×(1-15.37%)=1.69 GB/s
改进分散集聚DMA写一个描述符对应内存数据需要传输非有效数据的损耗如表2所示。
表2 改进DMA写一个描述符对应内存数据传输损耗

由表2可知,分散集聚DMA数据上行过程中,对于每一个描述符中内存地址以及数据长度的发送,需要损耗的字节数为8+4+3×8=36,每传输一个描述符内存数据(4 096 B),需要传输的TLP包个数为4 096/128=32,每传输一个TLP包的字节损耗是12+8=20,传输4 096 B有效数据损耗共计
32×20+36=676 B
所以,分散集聚DMA数据上行的损耗为
676/(4 096+676)=14.17%
改进DMA有效数据上行传输速度极限为
2×(1-14.17%)=1.72 GB/s
所以,改进DMA有效数据上行极限传输速度较现有分散集聚DMA提升为
(1.72-1.69)/1.69=1.78%
同样的方法可以计算出数据下行(DMA读)的有效数据极限传输速度提升为
(1.52-1.50)/1.50=1.33%
由计算可知,从传输数据包中有效数据比例的角度分析,改进后的分散集聚DMA数据上行、下行的有效数据极限传输速度均有提升。
4 性能测试
分散集聚DMA性能测试的结构设计如图5所示,主要分为上位机和FPGA两个模块。上位机的用户程序通过基于WDF的驱动实现内存与FPGA之间的数据传输,并能够计算出数据传输速率;FPGA中的DMA控制器通过Xilinx封装的IP硬核实现与上位机之间控制信号以及数据的传输,DMA控制器还可以根据上位机的设定实现通道选择。
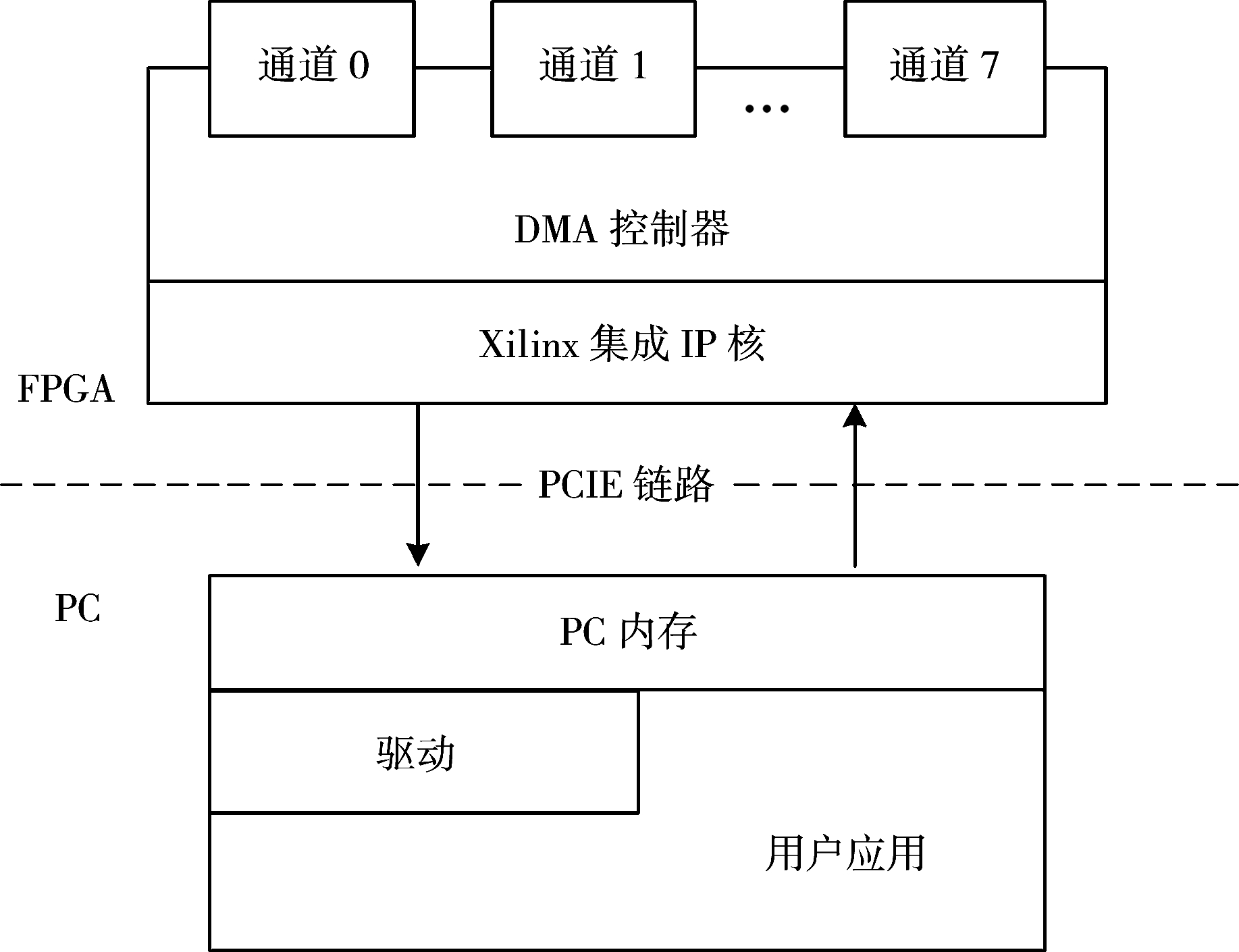
图5 性能测试结构
实际的测试过程是在上位机申请两块相同大小的内存A,B,在用户程序中先将内存A写入数据,启动DMA读操作,将数据写入通道0,完成DMA读操作后,启动DMA写操作,将数据写入内存B中,然后比较内存A,B中的数据,若两者数据一致,表示DMA读写操作成功。性能测试如图6所示。

图6 性能测试
由于各个通道间寄存器完全一致,性能一样,本次测试选择通道0,DMA数据传输测试结果如表3所示。
表3 测试结果
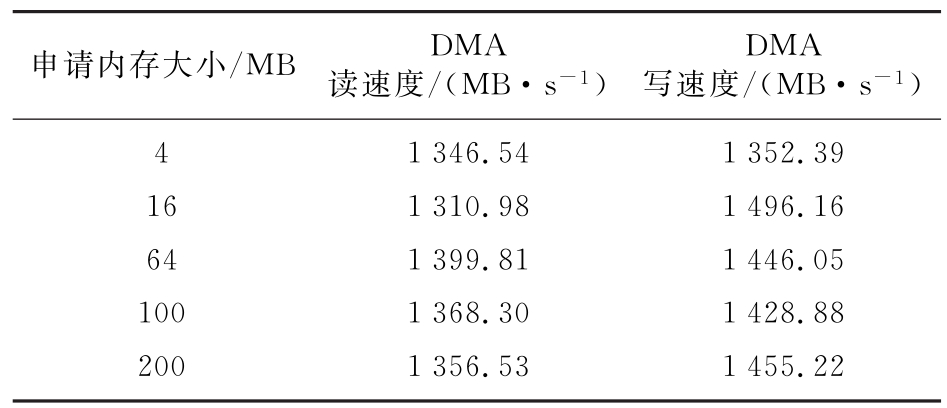
改进后的分散集聚DMA有效数据极限传输速度已经在第3节详细描述,由表3可知,DMA读(数据下行)速度最高可达到1 400 MB/s,达到理论极限带宽的92.11%,DMA写(数据上行)速度最高可达到1 500 MB/s,达到理论极限带宽的87.21%。
由于实际数据传输过程中,DMA控制器初始化、PCIE链路与CPU之间的传输延迟以及中断处理等客观原因,使得实际测试的速度不能达到理论极限速度,但本次测试的实际传输速度已很接近理论极限带宽。
在此基础上,本文实现了雷达数据记录回放系统的设计,如图7所示。以PCIE总线实现上位机与FPGA的数据传输,以光纤RapidIO接口实现FPGA与数据记录系统或信号处理系统的数据传输,以DDR3实现数据在板卡上的缓存。最终雷达数据传输能够达到光纤RapidIO接口的极限速度1 GB/s。
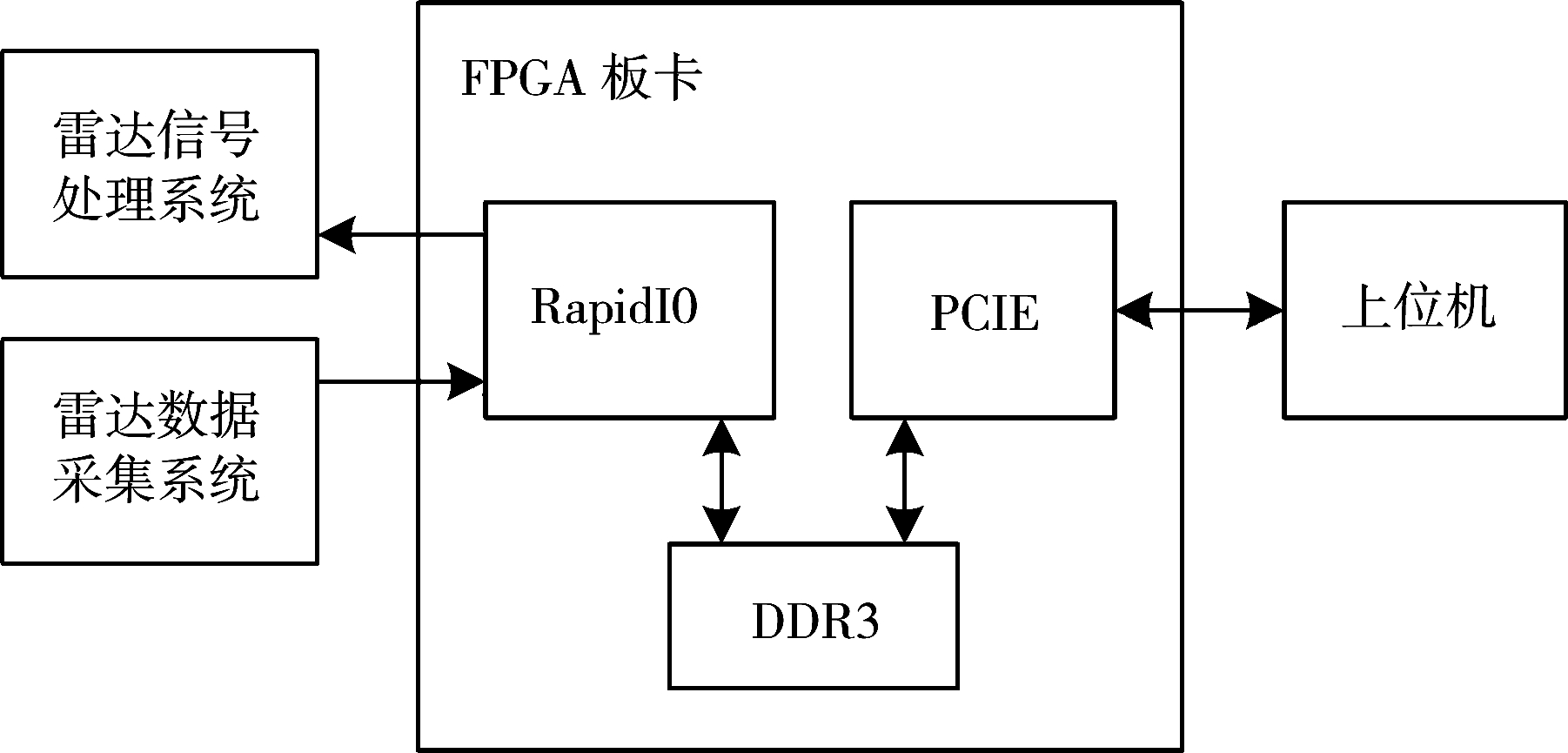
图7 雷达数据记录回放系统
5 结束语
基于PCIE总线的多通道分散集聚DMA作为一种高速的数据传输方式,在雷达数据记录回放系统中得到了广泛的应用。文中对现有分散集聚DMA提出了改进的方法,DMA读写极限传输速度较现有DMA均有提升,经过实际测试,单通道DMA写速度最高能达到1 500 MB/s,DMA读速度最高能达到1 400 MB/s。改进后的分散集聚DMA至多支持8个数据通道进行数据传输,可在实际应用中配合雷达信号处理系统实现雷达数据的流水传输与处理,能够满足雷达数据记录回放系统对数据传输的要求。
参考文献:
[1]徐国平.雷达视频回波信号记录与回放系统设计[J].电子设计工程,2015,23(9):135-137,141.
[2]孙高俊,刘志英.基于FPGA的雷达IQ光纤数据采集及传输系统[J].电子科技,2016,29(4):169-172.
[3]ROTA L,CASELLE M,CHILINGARYAN S,et al.A PCIe DMA Architecture for Multi-Gigabyte Per Second Data Transmission[J].IEEE Trans on Nuclear Science,2016,62(3):972-976.
[4]KAVIANIPOUR H,MUSCHTER S,BOHM C.High Performance FPGA-Based DMA Interface for PCIe[J].IEEE Trans on Nuclear Science,2014,61(2):745-749.
[5]张辉.DMA技术在煤矿高速数据采集系统中的应用[J].工矿自动化,2016,42(4):74-77.
[6]KIM D,MANAGULI R,KIM Y.Data Cache and Direct Memory Access in Programming Mediaprocessors[J].IEEE Micro,2001,21(4):33-42.
[7]李军伟,戴紫彬,南龙梅.密码SoC中嵌入式链式DMA的研究与设计[J].电子技术应用,2014,40(1):56-59.
[8]刘林海,张勇,常迎辉.光纤通道SOPC系统性能优化设计技术研究[J].无线电通信技术,2015,41(3):43-45.
[9]ZDENEK J.Distributed Control Computer Backbone Communication Channel of Electric Locomotive with Effective DMA Support[C]∥14th International Power Electronics and Motion Control Conference,Ohrid,Macedonia:IEEE,2010:27-34.
[10]王府北,王佳华,吴琼水.基于PCIe总线的显微镜图像采集系统设计[J].电子技术应用,2015,41(2):42-44.
[11]XILINX INC.Bus Master DMA Performance Demonstration Reference Design for the Xilinx Endpoint PCI Express Solutions[EB/OL].[2016-11-06].https:∥china.xilinx.com/support/documentation/application_notes/xapp1052.pdf
[12]肖文君,刘万松,刘伍丰,等.基于WDF的PCIe总线驱动程序设计与实现[J].测控技术,2015,34(7):101-104.
[13]贾玉姣,刘亚斌,张秀磊.基于高速多通道采集模块的数字化仪软件设计[J].电子设计工程,2016,24(12):77-80.
[14]SUN G,HE Z.A Real-Time Multi-Channel Signal Acquisition Card Based on PCI Express Interface[C]∥2009 International Conference on Communication Software and Networks,Macau:IEEE,2009:20-24.
[15]LI Y,CHANG T,BAI F,et al.Design of Multi-Channel Image Superimposition System Based on FPGA[C]∥2010 International Conference on Optoelectronics and Image Processing,Haiko:IEEE,2010:417-420.
