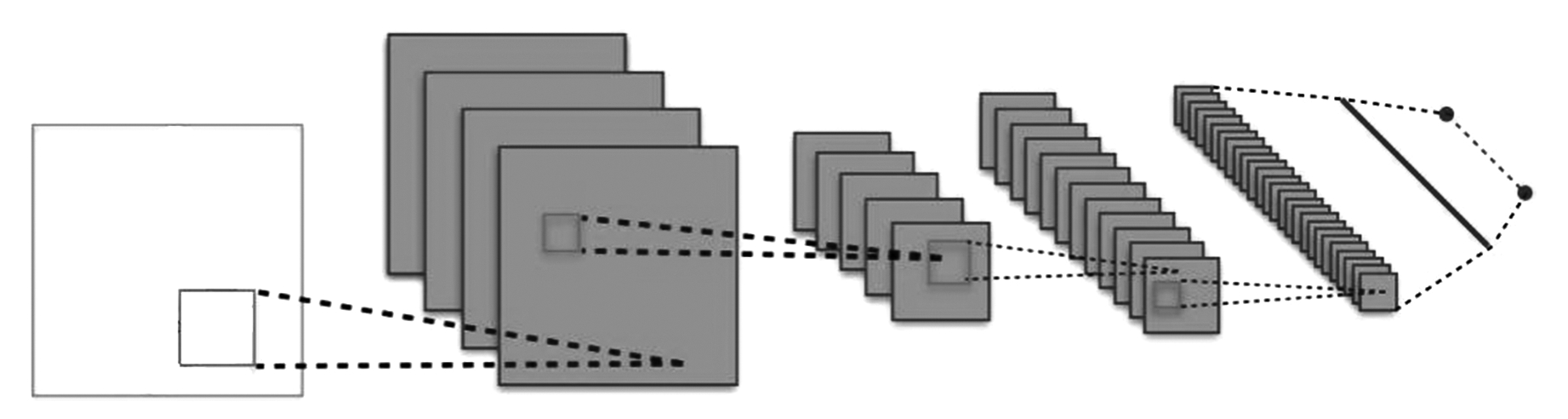
图1 卷积神经网络结构图
合成孔径雷达(Synthetic Aperture Radar,SAR)是一种基于飞机、卫星、宇宙飞船等多种平台的主动式对地观测系统,能全天时、全天候对地面进行观测。随着SAR系统与成像技术的不断进步与完善,大量的SAR图像需要处理,因此从众多基于复杂场景的图像中获取特征信息并应用于目标检测、目标分类和识别、场景分类等问题成为了SAR图像解译领域的研究趋势。传统的SAR图像场景分类关键环节是为图像建立一种有效的表示,使得这种表示既能稳定地获取反映场景类别的结构信息,又能抑制纹理等细节上的不显著差异[1]。SIFT[2]和GIST[3]是两种比较常见的图像描述特征,对平移、缩放及遮挡等情况具有稳定的辨别能力。以上针对SAR图像的目标和场景分类的研究均基于人为设计的特征描述,对提取的特征在分类问题上的稳定性要求较高,并且由于这些特征通常都是单一的基于目标的底层或中层视觉特征,因此针对大的数据集往往无法获得充分表征数据的本质属性,导致分类性能较差。
深度学习是一种基于人工神经网络的机器学习算法,通过一种深层神经网络逐层提取数据的底层到高层特征,获取数据的分布式特征表示。近年来,深度学习模型在图像识别与分类领域展现出了强大的学习能力,在Image Net数据集上一种深度神经网络将错误率从之前的26%降到了15%[4]。随后许多学者在不同的应用背景下提出了多种深度学习模型如栈式消噪自动编码机[5]、深度置信网络和卷积神经网络等。卷积神经网络作为一种基于局部感受野视觉原理的深度学习框架,图像可直接作为网络的输入,是一种端到端的网络模型。目前卷积神经网络在图像识别领域取得了广泛的应用,如人脸识别[6]、行为识别[7]、医学图像识别[8]等。
针对SAR图像目标和场景分类问题,本文提出一种改进的卷积神经网络算法。首先针对训练样本较少问题,采用数据增强的方法从已有数据中产生一批新的数据;然后利用卷积层局部感受野和权值共享的特点减少网络参数,并引入ReLU非线性激活函数加速网络的收敛;针对高层卷积层参数过多的问题,采用了一种多尺度模块替代卷积层;输出层采用卷积和全局均值池化的组合替代全连接层。实验结果表明,该算法具有较好的分类效果。
卷积神经网络(Convolutional Neural Network,CNN)是人工神经网络中的一种监督学习网络,目前已成为当前语音分析和图像识别与分类领域的研究热点。CNN的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。卷积网络是为识别二维形状而特殊设计的一个多层感知器,这种网络结构对平移、比例缩放、倾斜等图像变形具有高度不变性。在CNN中,图像的一小部分即局部感受野作为层级网络结构的底层输入,每层通过一个数字滤波器去获得观测数据最显著的特征,特征信息再依次传输到更高的层。卷积神经网络基本结构示意图如图1所示。
图1 卷积神经网络结构图
卷积神经网络作为一种由数据驱动的监督式学习网络,通常需要大量的数据作为支撑,才能获得较好的分类效果。针对卷积神经网络训练过程中因数据量较小引起的过拟合问题,在训练样本准备阶段,采用数据增强(Data Augmentation)的方法通过平移、翻转、加噪声等方法从已有数据中产生出一批新的数据,人工增加了训练样本的大小。
2.2.1 卷积层
在卷积层,基于局部感受野的人体视觉原理,将输入图像或上一层的特征图与该层的卷积滤波器进行卷积加偏置,通过一个非线性激活函数输出卷积层的输出特征图(feature map):
![]() *xl-1+bj
*xl-1+bj
(1)
fc=f(y)
(2)
式中,xl-1为上一层输出的特征图,k为卷积核,b为偏置,“*”为卷积计算,f ()为非线性激活函数,fc为卷积层的输出特征图。选择ReLU函数作为卷积层的非线性激活函数。常用的非线性激活函数如sigmoid和tanh由于其正负饱和区的梯度都接近于0,会出现梯度弥散[9]问题,而ReLU函数在对应输入大于0的部分梯度为常数,因此有效地避免了梯度弥散的出现[10]。
2.2.2 池化层
在卷积神经网络中,由于图像直接作为网络的输入且卷积滤波器会输出大量的特征图,为了减少待处理数据的数量,需要对网络中产生的特征图进行降维。在池化层,对卷积层的输出特征图进行下采样,实现数据的降维。均值和最大值是目前常用的两种池化方式。本算法采用最大值池化作为下采样方式,输出池化区域中的最大值:
Rl=max(Rl-1)
(3)
式中,Rl-1表示上一层的输出特征图中对应的一个池化区域,Rl表示该池化区域的最大值下采样输出。
2.2.3 多尺度卷积模块
卷积神经网络在图像识别领域已经展现了其强大的学习能力,目前提高卷积神经网络性能最直接的方法就是增加网络的深度,以提升网络对数据的表征能力。但网络深度的增加意味着参数的增加,这使得扩大后的网络易出现过拟合的问题。针对这一问题,在参数较多的高层卷积层,采用一种多尺度卷积模块(Inception)[11]替代高层卷积层,在保证网络深度的同时,减少了网络参数数量。多尺度卷积模块示意图如图2所示。
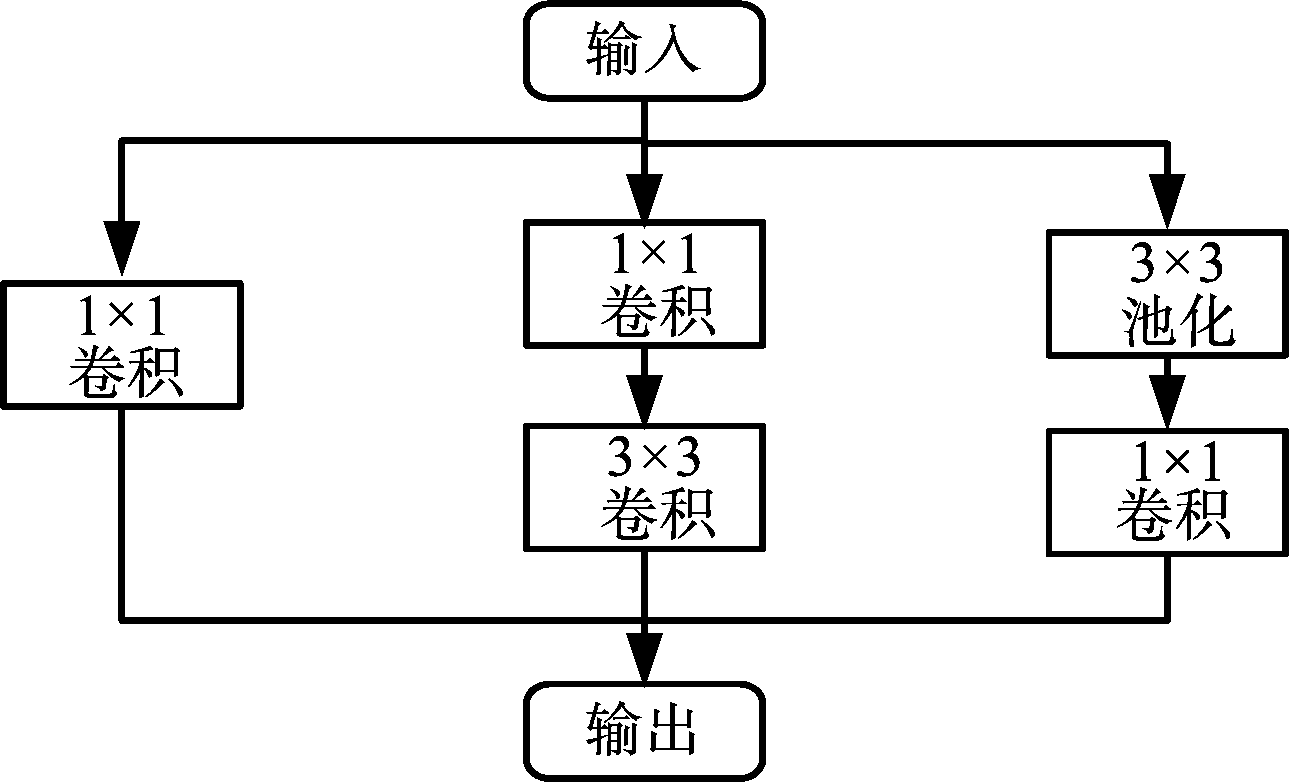
图2 多尺度卷积模块
该模块包含3种尺度的卷积和池化操作,其中3×3的卷积和3×3的最大值池化在模块中作为过滤器实现数据特征提取,1×1的卷积主要起到特征图降维的效果。通过多尺度卷积模块的引入,增加了网络的深度和宽度,同时相比于传统卷积层单一尺度的卷积操作,多尺度模块的输出特征图包含了更丰富的特征信息。
2.2.4 卷积和全局均值池化
传统的CNN通过全连接层整合特征图信息输出分类结果,而CNN中大部分训练参数集中于全连接层,过多的网络参数往往带来训练收敛效果差和过拟合的问题。在本文算法中,采用卷积层和全局均值池化(Global Average Pooling,GAP)的组合作为CNN的输出层,卷积层输出为个数为N的特征图(分别对应样本的N个类别),然后通过一个全局均值池化将这N个特征图降维成1×1的尺寸,最后采用Softmax进行归一化,输出对应类别的概率。由于卷积是一种局部连接的神经元输出,相比较与全连接层,这种组合能有效地减少网络的参数。Softmax回归模型是logistic回归模型在多分类问题上的推广,对于给定的输入x,Softmax的回归模型定义如下:
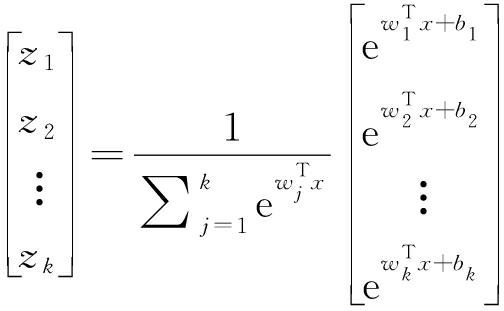
(4)
式中,zk表示第k个神经元的输出,wT和b分别表示权重和偏置。由式(4)可以看出,Softmax回归模型把神经元的输出映射到0~1之间,同时起到了归一化的作用。该算法中误差函数定义为交叉熵误差函数:
E=-∑kyklnzk
(5)
式中,zk表示神经元实际输出,yk表示对应于第k类的真实值,取值为0或1。
图3为改进的基于卷积神经网络的SAR图像目标识别算法流程图。具体步骤如下:
1) SAR图像数据集通过数据增强处理,得到的扩充训练样本作为卷积神经网络的输入;
2) 根据高斯分布随机初始化方法,对卷积层和全连接层的权重和偏置进行初始化;
3) 卷积神经网络训练:
① 根据式(1)、式(2)计算卷积,采用ReLU函数对卷积结果进行非线性,得到卷积层的特征图;
② 根据式(3)对上一层的特征图进行最大值下采样,输出池化层的特征图;
③ 将经卷积和池化操作提取到的特征图输入到多尺度卷积模块,得到该层的特征图输出;
④ 将先前层提取到的特征图通过卷积和全局均值池化,输出对应各类的特征图,最后利用Softmax回归模型输出对应类别概率,根据式(4)得到识别结果;
⑤ 根据式(5)计算网络权值和偏置的梯度,采用梯度下降法进行误差反向传播,从而调整网络参数。
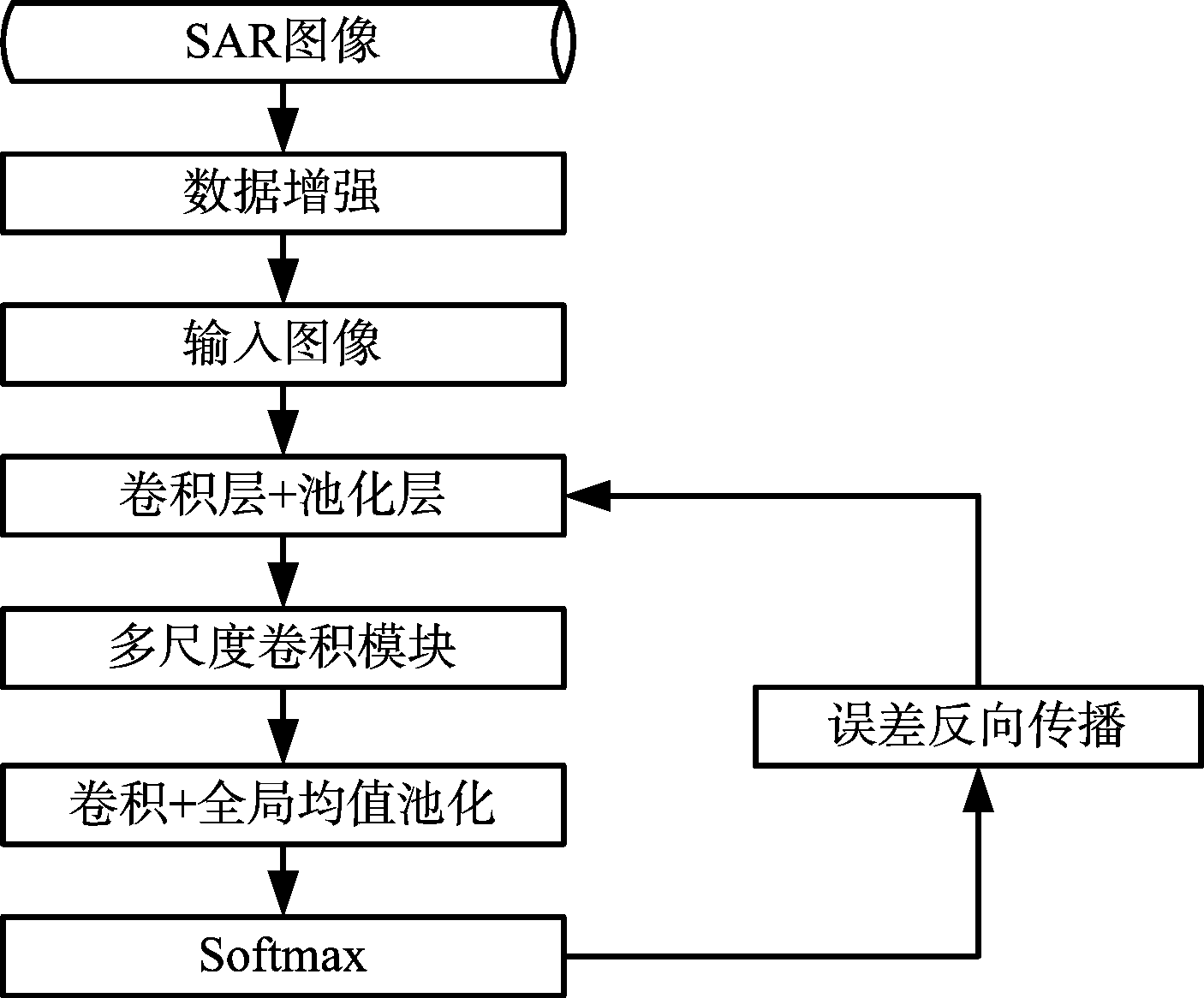
图3 算法流程图
为了验证算法的有效性,分别采用美国国防部高级研究计划局(DARPA)支持的MSTAR公开数据集和陕西渭南地区的高分辨率SAR图像进行目标和场景分类实验。实验基于caffe深度学习框架构造卷积神经网络,具体环境为:i7-6700(3.4 GHz,四核),16 GB内存,卷积神经网络训练过程采用GPU加速。
3.1.1 卷积神经网络框架配置与数据分布
针对MSTAR数据集,构建一个包含5个卷积层、5个池化层和1个多尺度卷积模块的卷积神经网络,网络框架配置如表1所示。将数据增强后的MSTAR数据集训练样本直接作为网络的输入,最终输出层输出一个N维的向量,对应于N个类别的概率。
表1 CNN框架配置

网络层卷积/池化窗口大小输入—卷积层-15×5×20池化层-12×2卷积层-25×5×40池化层-22×2卷积层-34×4×80池化层-32×2卷积层-43×3×160多尺度卷积层—池化层-42×2卷积层-5+GAP3×3×10+2×2Softmax—
MSTAR数据集是通过高分辨率的聚束式合成孔径雷达采集到的静止车辆的SAR切片图像,包括多类目标SAR图像数据。实验中,训练样本为17°方位角的SAR图像数据,测试样本为15°方位角的SAR图像数据。在10类目标识别实验中,实验数据包括BMP2,BTR70,T72,2S1,BRDM2,ZSU234,BTR60,D7,T62,ZIL131十类目标数据。采用数据增强对训练样本进行扩充,通过像素平移的方法使得每类训练数据在原有基础上扩充了5倍,10类目标测试与训练数据分布如表2所示。
表2 10类目标测试与训练数据分布
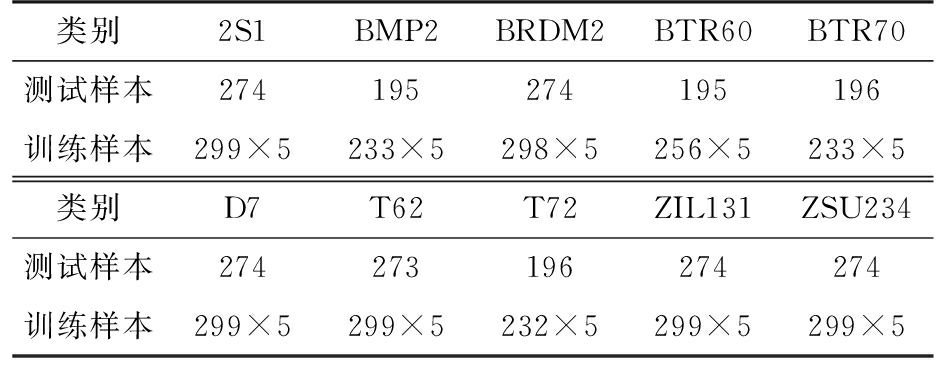
类别2S1BMP2BRDM2BTR60BTR70测试样本274195274195196训练样本299×5233×5298×5256×5233×5类别D7T62T72ZIL131ZSU234测试样本274273196274274训练样本299×5299×5232×5299×5299×5
采用批量随机梯度下降法(Mini-Batch Stochastic Gradient Descent,MSGD)训练网络,batchsize设置为25,学习率设置为0.001,训练迭代60 000次,10类目标的最终分类结果如表3所示。
表3 10类目标分类结果
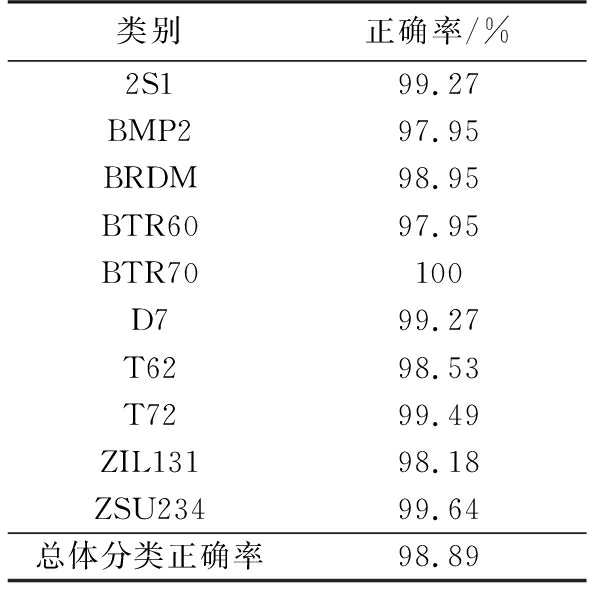
类别正确率/%2S199.27BMP297.95BRDM98.95BTR6097.95BTR70100D799.27T6298.53T7299.49ZIL13198.18ZSU23499.64总体分类正确率98.89
3.1.2 不同框架对比
为了更好地评测本文算法提出的框架的性能,构建一个与本文算法框架具有相同网络层数的CNN框架进行对比。在网络的前4个卷积层,对比框架与本文算法框架具有相同的卷积核尺寸和数量;为了对比不同结构作为网络输出层的效果,对比框架的输出层设置为全连接层。两个CNN框架具体参数如表4所示,其中CNN-1为本文算法的框架,CNN-2为对比框架,加粗数字指网络中的训练参数。
表4 网络框架参数对比
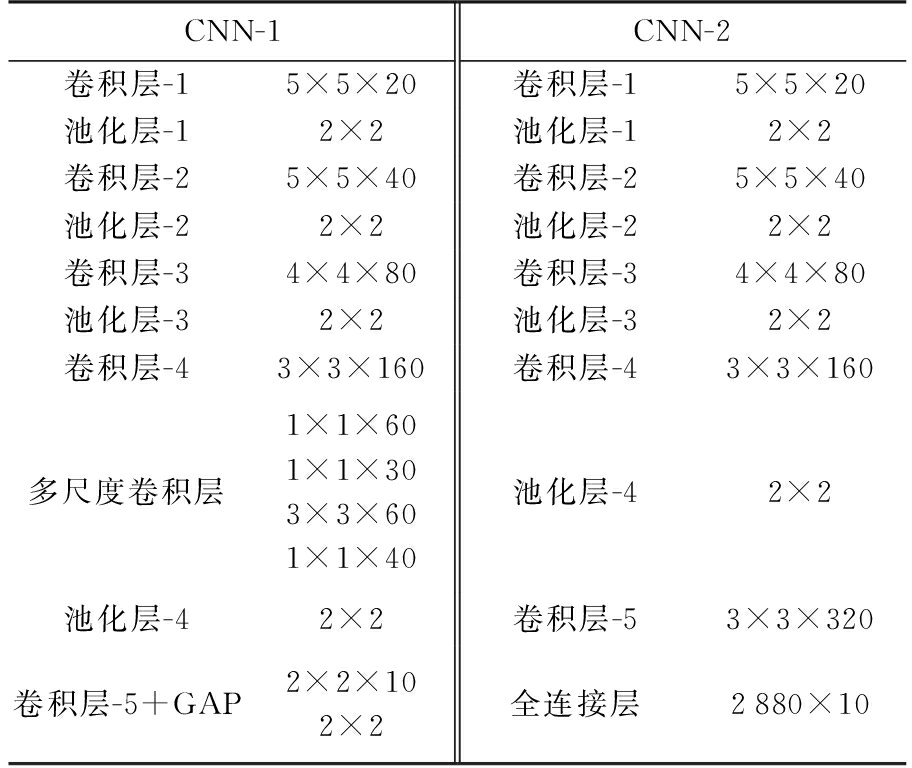
CNN-1CNN-2卷积层-15×5×20卷积层-15×5×20池化层-12×2池化层-12×2卷积层-25×5×40卷积层-25×5×40池化层-22×2池化层-22×2卷积层-34×4×80卷积层-34×4×80池化层-32×2池化层-32×2卷积层-43×3×160卷积层-43×3×160多尺度卷积层1×1×601×1×303×3×601×1×40池化层-42×2池化层-42×2卷积层-53×3×320卷积层-5+GAP2×2×102×2全连接层2880×10
由表4可以计算出CNN-1网络训练参数为 4 930,CNN-2网络训练参数为35 900,CNN-1相比较于CNN-2参数减少了86%。两个CNN框架均基于caffe平台构建,训练样本为MSTAR的10类数据,训练过程最大迭代次数为60 000次,训练和测试的训练误差和测试正确率曲线如图4和图5所示。
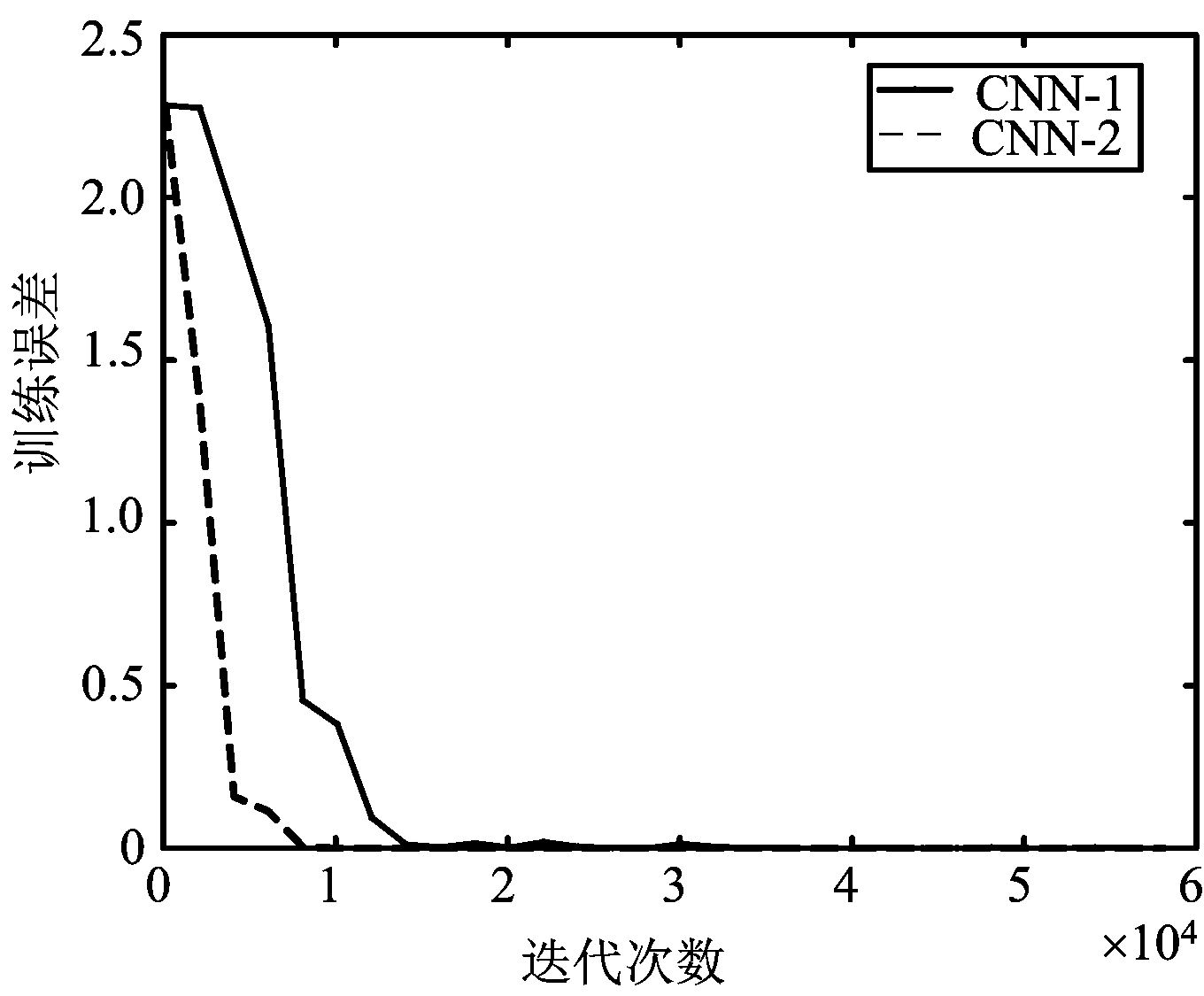
图4 误差对比曲线
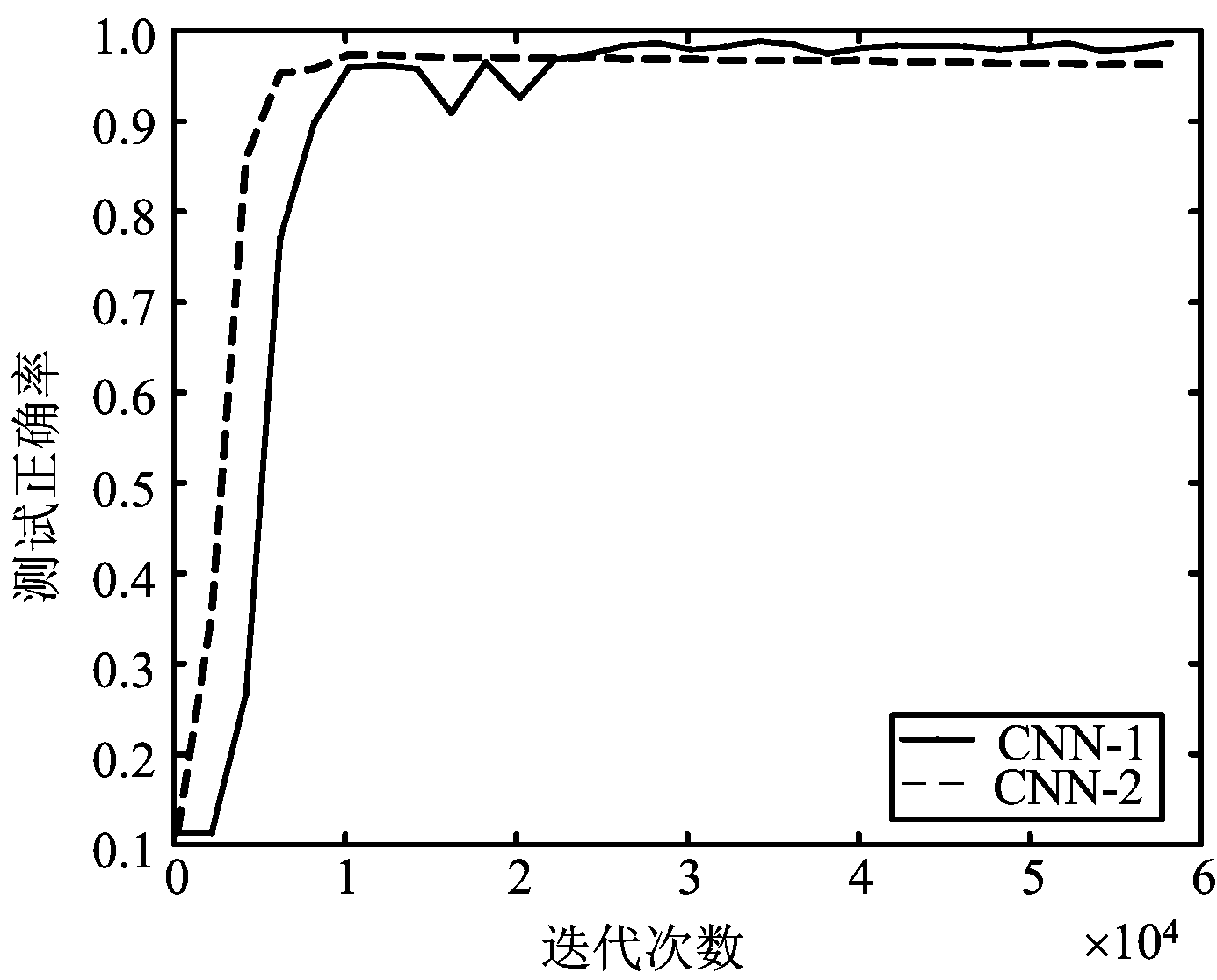
图5 测试正确率对比曲线
由训练误差曲线可以看出,两个CNN框架在训练迭代15 000次后误差已基本达到收敛,其中CNN-1收敛速度较慢,可能的原因是多尺度模块的引入,导致梯度在反向传播时计算量增加。由测试正确率曲线可以看出,在迭代约24 000次后,CNN-1的测试正确率已超过CNN-2,且正确率大小整体趋于稳定。
实验采用陕西渭南地区的机载高分辨率SAR图像(分辨率为1 m)进行场景分类,通过Photoshop工具对尺寸为7 420×10 788的原始高分辨率SAR图像截取出667张包含3类SAR图像场景的局部SAR图像,尺寸为500×500,以8∶2的比例分配给卷积神经网络作为训练及测试样本。3类(农田、城镇、高架桥)SAR局部场景图像如图6所示。

(a) 农田 (b) 城镇 (c) 高架桥
图6 3类SAR场景图像
针对高分辨率SAR图像场景分类问题,构建一个卷积神经网络如表5所示。训练样本准备阶段,首先采用最大值下采样池化对尺寸为500×500的局部SAR图像进行降维;然后通过数据增强的方法,将图像分别旋转4个角度,使得训练样本的数量扩充为原来的4倍。
表5 CNN框架配置

网络层卷积/池化窗口大小输入—卷积层-111×11×20池化层-12×2卷积层-28×8×40池化层-22×2卷积层-35×5×80池化层-32×2卷积层-45×5×160池化层-42×2卷积层-55×5×320多尺度卷积层—池化层-52×2卷积层-6+GAP3×3×3+2×2Softmax—
采用批量随机梯度下降法训练网络,batchsize设置为27,学习率设置为0.001,训练迭代50 000次,3类SAR场景的最终测试分类结果如表6所示。由表6所示可以得出本文算法在3类SAR图像场景分类上取得了较好的分类精度。
表6 场景分类结果
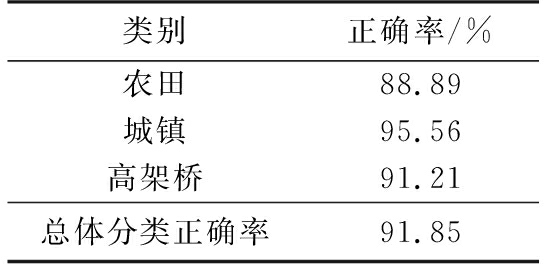
类别正确率/%农田88.89城镇95.56高架桥91.21总体分类正确率91.85
本文针对SAR图像目标和场景分类问题,提出了一种改进的基于卷积神经网络的SAR图像分类算法。针对数据集训练样本较少的问题,采用数据增强的方法人工地增加训练样本的大小;为了解决卷积神经网络中因网络参数过多导致的过拟合问题,采用一种多尺度卷积模块替代高层卷积层,在输出层采用卷积和全局均值池化的组合替代全连接层。分别对MSTAR数据集和陕西渭南地区的高分辨率SAR图像进行目标和场景分类实验,本文算法针对MSTAR 10类目标和高分辨率SAR图像3类场景的分类正确率分别达到了98.89%和91.85%;通过构建相同深度的卷积神经网络进行对比实验,结果表明,本文算法有效地解决了网络的过拟合问题。
[1] 李学龙,史建华,董永生,等. 场景图像分类技术综述[J]. 中国科学: 信息科学, 2015, 45(7):827-848.
[2] LOWE D G. Distinctive Image Features from Scale-Invariant Keypoints[J]. International Journal of Computer Vision, 2004, 60(2):91-110.
[3] OLIVA A, TORRALBA A. Modeling the Shape of Scene: A Holistic Representation of the Spatial Envelope[J]. International Journal of Computer Vision, 2001, 42(3):145-175.
[4] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet Classification with Deep Convolutional Neural Networks[C]∥ 25th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada: [s.n.], 2012:1097-1105.
[5] VINCENT P, LAROCHELLE H, LAJOIE I, et al. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion[J]. The Journal of Machine Learning Research, 2010, 11(12):3371-3408.
[6] MA Yukun, HE Jiaoyu, WU Lifang, et al. An Effective Face Verification Algorithm to Fuse Complete Features in Convolutional Neural Network[C]∥ 22nd International Conference on Multimedia Modeling, Miami, FL: Springer, 2016:39-46.
[7] IJJINA E P, MOHAN C K. Human Action Recognition Based on Motion Capture Information Using Fuzzy Convolution Neural Networks [C]∥ 8th International Conference on Advances in Pattern Recognition, Kolkata, India: IEEE, 2015:1-6.
[8] CIOMPI F, DE HOOP B, VAN RIEL S J, et al. Automatic Classification of Pulmonary Peri-Fissural Nodules in Computed Tomography Using an Ensemble of 2D Views and a Convolutional Neural Network out-of-the-Box[J]. Medical Image Analysis, 2015, 26(1):195-202.
[9] HINTON G E, SALAKHUTDINOV R R. Reducing the Dimensionality of Data with Neural Networks[J]. Science, 2006, 313(5786):504-507.
[10] GLOROT X, BORDES A, BENGIO Y. Deep Sparse Rectifier Neural Networks[C]∥ 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL: [s.n.], 2011:315-323.
[11] SZEGEDY C, LIU W, JIA Y, et al. Going Deeper with Convolutions[C]∥ IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA: IEEE, 2015:1-9.

